spark dataframe withcolumn|pyspark update existing column : iloilo You can do an update of PySpark DataFrame Column using withColum () transformation, select (), and SQL (); since DataFrames are distributed immutable collections, you can’t really . Resultado da Browse Getty Images' premium collection of high-quality, authentic Bianca Gray stock photos, royalty-free images, and pictures. Bianca Gray stock .
0 · what is withcolumn in pyspark
1 · pyspark withcolumn list
2 · pyspark update existing column
3 · pyspark update column by value
4 · pyspark select vs withcolumn
5 · pyspark dataframe withcolumns
6 · pyspark add column to dataframe
7 · dataframe withcolumn in spark
8 · More
OnlyFans is the social platform revolutionizing creator and fan connections. The site is inclusive of artists and content creators from all genres and allows them to monetize their .
spark dataframe withcolumn*******pyspark.sql.DataFrame.withColumn. ¶. DataFrame.withColumn(colName: str, col: pyspark.sql.column.Column) → pyspark.sql.dataframe.DataFrame [source] ¶. Returns a .
pyspark update existing column Spark withColumn () is a DataFrame function that is used to add a new column to DataFrame, change the value of an existing column, convert the datatype of.
DataFrame.withColumn (colName: str, col: pyspark.sql.column.Column) → pyspark.sql.dataframe.DataFrame¶ Returns a new DataFrame by adding a column or .
You can do an update of PySpark DataFrame Column using withColum () transformation, select (), and SQL (); since DataFrames are distributed immutable collections, you can’t really .
The withColumn function is a powerful transformation function in PySpark that allows you to add, update, or replace a column in a DataFrame. It is commonly used to create new . I want to do a conditional aggregation inside " withColumn " as follows: mydf.withColumn("myVar", if($"F3" > 3) sum($"F4") else 0.0) that is for every row .pyspark.sql.DataFrame.withColumns. ¶. DataFrame.withColumns(*colsMap: Dict[str, pyspark.sql.column.Column]) → pyspark.sql.dataframe.DataFrame [source] ¶. Returns a .Learn how to use the withColumn function in PySpark to perform column-based operations on DataFrames. See examples of renaming, changing data type, applying .
In this article, we are going to see how to add two columns to the existing Pyspark Dataframe using WithColumns. WithColumns is used to change the value, .pyspark.sql.DataFrame.withColumn. ¶. DataFrame.withColumn(colName: str, col: pyspark.sql.column.Column) → pyspark.sql.dataframe.DataFrame ¶. Returns a new DataFrame by adding a column or replacing the existing column that has the same name. The column expression must be an expression over this DataFrame; attempting to add .
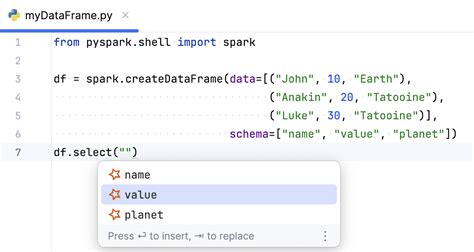
PySpark returns a new Dataframe with updated values. I will explain how to update or change the DataFrame column using Python examples in this article. Advertisements. Syntax. # Syntax. .spark dataframe withcolumn df.select("name").show(10) This will print first 10 element, Sometime if the column values are big it generally put "." instead of actual value which is annoying. Hence there is third option. df.select("name").take(10).foreach(println) Takes 10 element and print them. Now in all the cases you won't get a fair sample of the data, as the first .spark dataframe withcolumn pyspark update existing columnpyspark.sql.DataFrame.columns¶ property DataFrame.columns¶. Returns all column names as a list.The withColumn function is a powerful transformation function in PySpark that allows you to add, update, or replace a column in a DataFrame. It is commonly used to create new columns based on existing columns, perform calculations, or apply transformations to the data. With withColumn, you can easily modify the schema of a DataFrame by adding a . LOGIN for Tutorial Menu. In Spark SQL, select () function is used to select one or multiple columns, nested columns, column by index, all columns, from the list, by regular. Your function_definition(valor,atributo) returns a single String (valor_generalizado) for a single valor.. AssertionError: col should be Column means that you are passing an argument to WithColumn(colName,col) that is not a Column. So you have to transform your data, in order to have Column, for example as you can see .pyspark.sql.DataFrame.withColumnRenamed. ¶. Returns a new DataFrame by renaming an existing column. This is a no-op if the schema doesn’t contain the given column name. New in version 1.3.0. Changed in version 3.4.0: Supports Spark Connect. string, name of the existing column to rename. string, new name of the column.
In PySpark, you can cast or change the DataFrame column data type using cast() function of Column class, in this article, I will be using withColumn(), selectExpr(), and SQL expression to cast the from String to Int (Integer Type), String to Boolean e.t.c using PySpark examples.To apply any generic function on the spark dataframe columns and then rename the column names, can use the quinn library. Please refer example code: import quinn def lower_case(col): return col.lower() df_ = quinn.with_columns_renamed(lower_case)(df) lower_case is the function name and df is the initial spark dataframe You can use the function when to use conditionals. import org.apache.spark.sql.functions.when. mydf.withColumn("myVar", when($"F3" > 3, $"F4").otherwise(0.0)) But I don't get what do you want to sum, since there is a single value of F4 by row. EDIT If you want to aggregate first you can perform a groupBy and and .
It is a DataFrame transformation operation, meaning it returns a new DataFrame with the specified changes, without altering the original DataFrame. The “withColumn” function is particularly useful when you need to perform column-based operations like renaming, changing the data type, or applying a function to the values in a column. Syntaxisin. public Column isin( Object . list) A boolean expression that is evaluated to true if the value of this expression is contained by the evaluated values of the arguments. Note: Since the type of the elements in the list are inferred only during the run time, the elements will be "up-casted" to the most common type for comparison.
1. Introduction to PySpark DataFrame Filtering. PySpark filter() function is used to create a new DataFrame by filtering the elements from an existing DataFrame based on the given condition or SQL expression. It is similar to Python’s filter() function but operates on distributed datasets. It is analogous to the SQL WHERE clause and allows . You can use the function when to use conditionals. import org.apache.spark.sql.functions.when. mydf.withColumn("myVar", when($"F3" > 3, $"F4").otherwise(0.0)) But I don't get what do you want to sum, since there is a single value of F4 by row. EDIT If you want to aggregate first you can perform a groupBy and and .
It is a DataFrame transformation operation, meaning it returns a new DataFrame with the specified changes, without altering the original DataFrame. The “withColumn” function is particularly useful when you need to perform column-based operations like renaming, changing the data type, or applying a function to the values in a column. Syntax
isin. public Column isin( Object . list) A boolean expression that is evaluated to true if the value of this expression is contained by the evaluated values of the arguments. Note: Since the type of the elements in the list are inferred only during the run time, the elements will be "up-casted" to the most common type for comparison. 1. Introduction to PySpark DataFrame Filtering. PySpark filter() function is used to create a new DataFrame by filtering the elements from an existing DataFrame based on the given condition or SQL expression. It is similar to Python’s filter() function but operates on distributed datasets. It is analogous to the SQL WHERE clause and allows .pyspark.sql.DataFrame.filter. ¶. Filters rows using the given condition. where() is an alias for filter(). New in version 1.3.0. Changed in version 3.4.0: Supports Spark Connect. a Column of types.BooleanType or a string of SQL expressions. Filtered DataFrame. Filter by Column instances. dataframe with count of nan/null for each column. Note: The previous questions I found in stack overflow only checks for null & not nan. That's why I have created a new question. I know I can use isnull() function in Spark to find number of Null values in Spark column but how to find Nan values in Spark dataframe?
1. Create DataFrame from RDD. One easy way to manually create PySpark DataFrame is from an existing RDD. first, let’s create a Spark RDD from a collection List by calling parallelize () function from SparkContext . We would need this rdd object for all our examples below.
Quickstart: DataFrame¶. This is a short introduction and quickstart for the PySpark DataFrame API. PySpark DataFrames are lazily evaluated. They are implemented on top of RDDs. When Spark transforms data, it does not immediately compute the transformation but plans how to compute later. When actions such as collect() are explicitly called, the . I am currently using HiveWarehouseSession to fetch data from hive table into Dataframe by using hive.executeQuery(query) pyspark; Share. Improve this question. Follow edited Sep 15, 2022 at 6:59. ZygD. 23.7k 40 40 . create a spark dataframe column consists of a list as data type. 1. Pyspark dataframe to python list. 1. Pyspark - Loop .
The dataset in ss.csv contains some columns I am interested in:. ss_ = spark.read.csv("ss.csv", header= True, inferSchema = True) ss_.columns ['Reporting Area', 'MMWR Year', 'MMWR Week', 'Salmonellosis (excluding Paratyphoid fever andTyphoid fever)†, Current week', 'Salmonellosis (excluding Paratyphoid fever andTyphoid fever)†, . Well thanks to you I got to relearn something I forgot in my spark class. You can't call directly your custom functions with WithColumn, you need to use UserDefinedFunctions (UDF) Here is a quick example of how I got a custom function to work with your dataframe (StringType is the return type of the function)alias (*alias, **kwargs). Returns this column aliased with a new name or names (in the case of expressions that return more than one column, such as explode). asc (). Returns a sort expression based on the ascending order of the column.
Snowdrop. Nenhuma descrição adicionada. Seguir Coleção. Curadoria de tu2dale_879. Seguidores. 168. Programas. Comentários. Assista programas de TV e filmes asiáticos .
spark dataframe withcolumn|pyspark update existing column